Overview
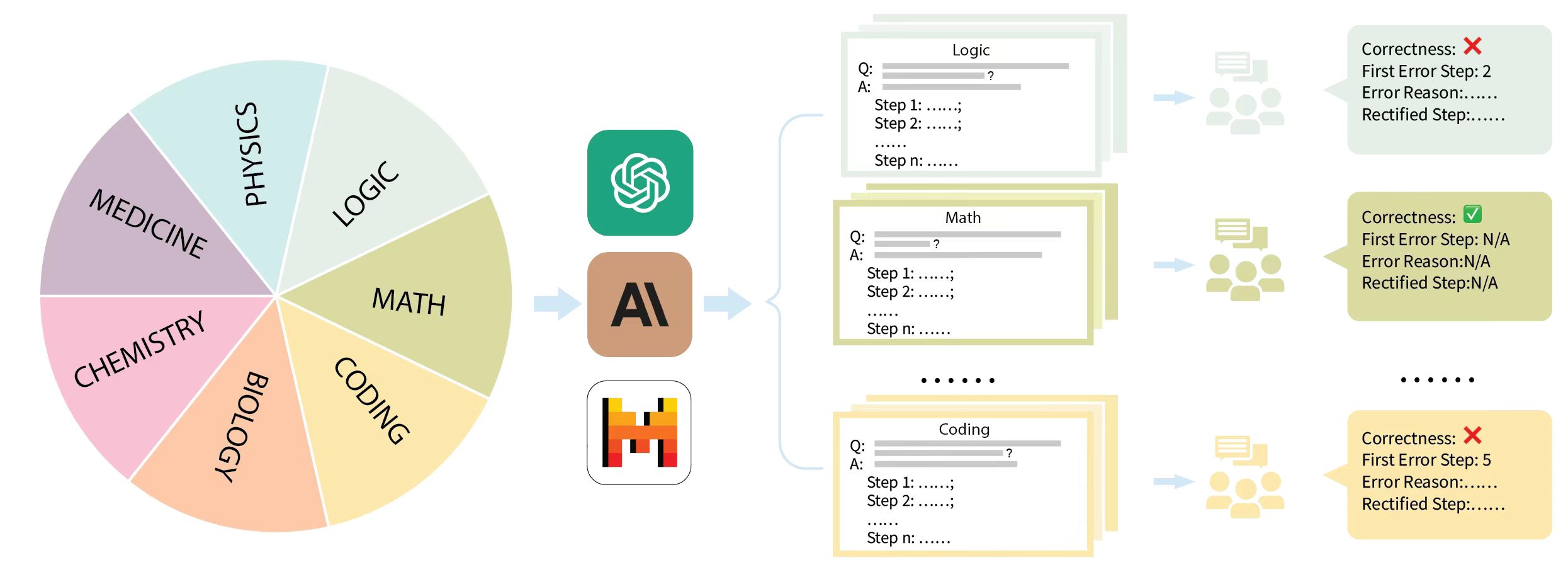
Figure 1: This is the illustration of the dataset creation pipeline of Mr-Ben.
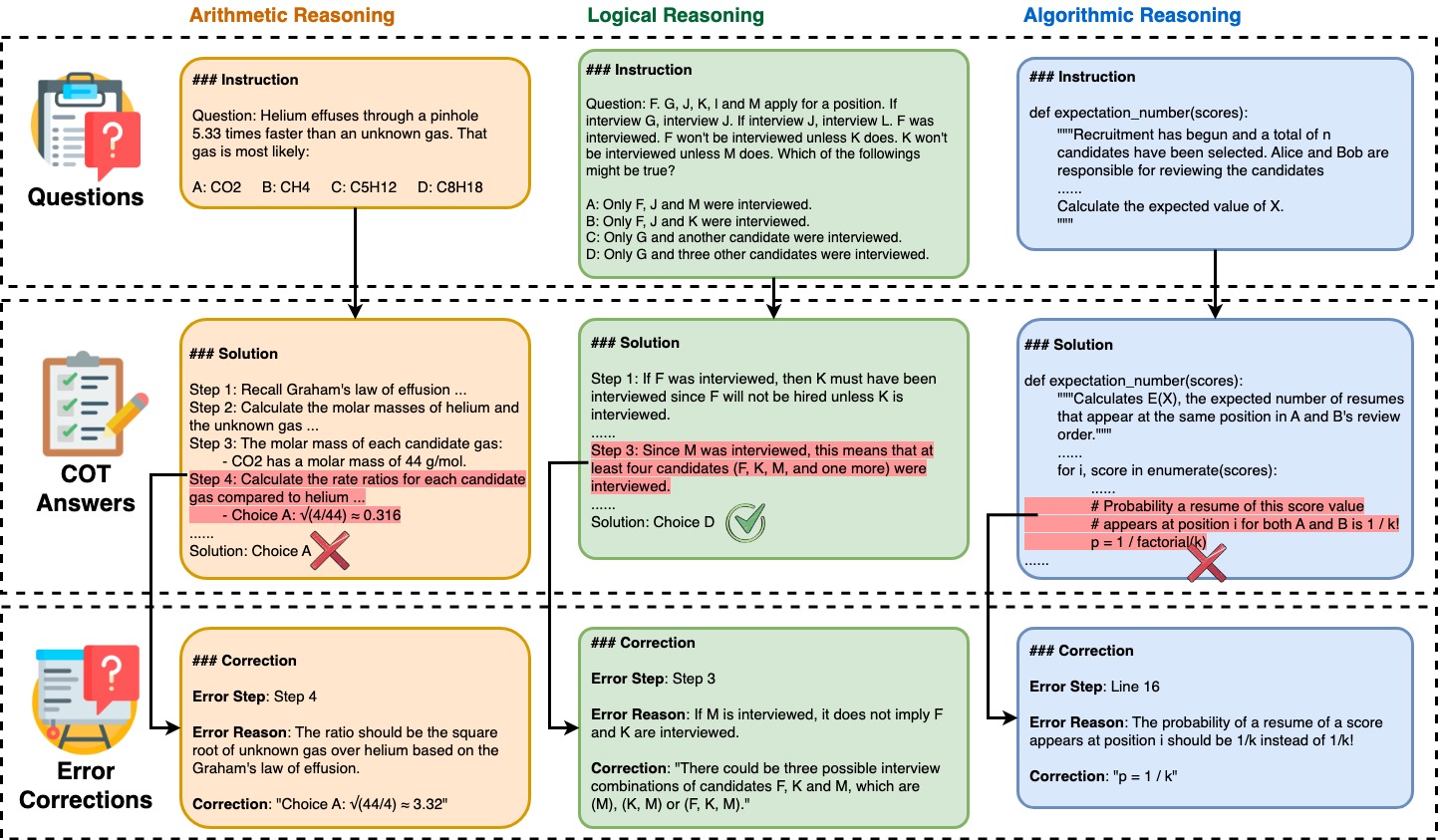
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-Ben that demands a meta-reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. Our meta-reasoning paradigm is especially suited for system-2 slow thinking, mirroring the human cognitive process of carefully examining assumptions, conditions, calculations, and logic to identify mistakes. MR-Ben comprises 5,975 questions curated by human experts across a wide range of subjects, including physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, with models like the o1 series from OpenAI demonstrating strong performance by effectively scrutinizing the solution space, many other state-of-the-art models fall significantly behind on MR-Ben, exposing potential shortcomings in their training strategies and inference methodologies.
| Model | #params | Avg Mr-Score (k=0) | Avg Mr-Score (k=1) | Cost-Per-Million-Tokens |
|---|---|---|---|---|
| Closed-source Model | ||||
| Claude3-Haiku | - | 4.4 | 3.1 | Input:$0.25/Output:$1.25 |
| GPT-3.5-Turbo | - | 4.0 | 5.5 | Input:$1.0/Output:$2.0 |
| Doubao-pro-4k | - | 8.8 | 11.6 | Input:$0.11/Output:$0.28 |
| Mistral-Large | - | 21.3 | 23.8 | Input:$4.0/Output:$12.0 |
| Yi-Large | - | 32.2 | 32.3 | Input:$3.0/Output:$3.0 |
| Moonshot-v1-8k | - | 32.5 | 33.0 | Input:$1.65/Output:$1.65 |
| GPT-4o-mini | - | 37.0 | 33.1 | Input:$0.15/Output:$0.60 |
| Claude3.5-Sonnet | - | 33.5 | 37.6 | Input:$3.0/Output:$15.0 |
| Gemini-1.5-Pro-Latest | - | 35.3 | 37.1 | Input:$3.5/Output:$10.5 |
| Zhipu-GLM-4 | - | 38.7 | 39.4 | Input:$13.78/Output:$13.78 |
| GPT-4-Turbo-2024-04-09 | - | 43.2 | 44.7 | Input:$10.0/Output:$30.0 |
| GPT-4o-2024-05-13 | - | 45.8 | 45.5 | Input:$5.0/Output:$15.0 |
| o1-mini-2024-09-12 | - | 51.0 | 50.8 | Input:$3.0/Output:$12.0 |
| o1-preview-2024-09-12 | - | 58.9 | 59.8 | Input:$15.0/Output:$60.0 |
| Open-source models Small | ||||
| Qwen1.5 | 1.8B | 0.0 | 0.0 | N/A |
| Gemma | 2B | 0.1 | 0.2 | N/A |
| Qwen2 | 1.5B | 2.1 | 5.4 | N/A |
| Phi-3-Mini | 3.8B | 11.9 | 11.0 | N/A |
| Open-source models medium | ||||
| GLM-4 | 9B | 6.7 | 2.1 | N/A |
| Deepseek-llm | 7B | 3.7 | 3.6 | N/A |
| Deepseek-Coder | 33B | 7.0 | 6.3 | N/A |
| Deepseek-Coder | 7B | 10.2 | 10.2 | N/A |
| Llama-3 | 8B | 12.2 | 9.8 | N/A |
| Yi-1.5 | 9B | 10.2 | 12.6 | N/A |
| Open-source models large | ||||
| Qwen-1.5 | 72B | 11.5 | 13.3 | N/A |
| Deepseek-llm | 67B | 15.2 | 16.5 | N/A |
| Llama-3 | 70B | 19.2 | 20.2 | N/A |
| Llama-3.1 | 70B | 30.9 | 27.5 | N/A |
| Deepseek-coder-v2-0614 | 236B | 25.0 | 31.7 | N/A |
| Deepseek-chat-v2-0517 | 236B | 30.2 | 32.3 | N/A |
| Qwen-2 | 72B | 33.3 | 34.2 | N/A |
@article{zeng2024mrben,
author = {Zhongshen Zeng and Yinhong Liu and Yingjia Wan and Jingyao Li and Pengguang Chen and Jianbo Dai and Yuxuan Yao and Rongwu Xu and Zehan Qi and Wanru Zhao and Linling Shen and Jianqiao Lu and Haochen Tan and Yukang Chen and Hao Zhang and Zhan Shi and Bailin Wang and Zhijiang Guo and Jiaya Jia},
title = {MR-Ben: A Meta-Reasoning Benchmark for Evaluating System-2 Thinking in LLMs},
journal = {CoRR},
volume = {abs/2406.13975},
year = {2024},
url = {https://arxiv.org/abs/2406.13975},
eprinttype = {arXiv},
eprint = {2406.13975}
}